
Notice
Recent Posts
Recent Comments
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 카메라
- 손무
- 올포스트
- 경영전략
- research
- ad
- 브랜드
- 리서치
- 60d
- 손자병법 활용
- 차가운바다
- 광고
- 경영전쟁
- 광고조사
- Dslr
- 손자
- Advertisement
- frozensea
- Marketing
- cmos00
- 광고학개론
- 커뮤니케이션
- olpost
- communication
- 마케팅
- 심리학
- 대인관계
- 손자병법
- 소비자
- 매체
Archives
- Today
- Total
cmos00
k-평균 군집 분석 (k-means clustering) 본문
1. 개념
- 데이터 분석 후 이를 특정 군집으로 묶는 방법론
- k값은 군집을 몇개로 정의할 것인지에 대한 숫자를 의미
2. k값을 구하는 방법

- CCC 통계량 (Cubit Clustering Criterion)
- 군집수 증가에 따라 (x축), CCC 통계량이 어떻게 변하는 지 (y축) 표시
- 이를 통해 가장 높은 y축 값을 보인 x축 (군집수)의 값 중 적합한 모수를 보이는 값을 k값으로 채택 (ex. 19가 1안, 3이 2안, 12이 3안 순으로 적합)

- 스크리 도표
- 요인 증가에 따라 (x축), 고윳값 (y축)이 어떻게 변하는 지 표시
- 요인이 증가할 때 경사가 갑자기 가파르게 감소하는 구간 직전 값을 k값으로 선택 (ex. 2)
- 단, 가파른 구간까지 요인이 너무 커질 경우 (ex. 10, 20, 30...으로 커진 경우) 고윳값이 1이상인 값 중 선택 (고윳값이 1보다 큰 주성분들이 충분한 정보를 포함하고 있음을 의미)
- 고윳값: 요인이 가지는 중요도
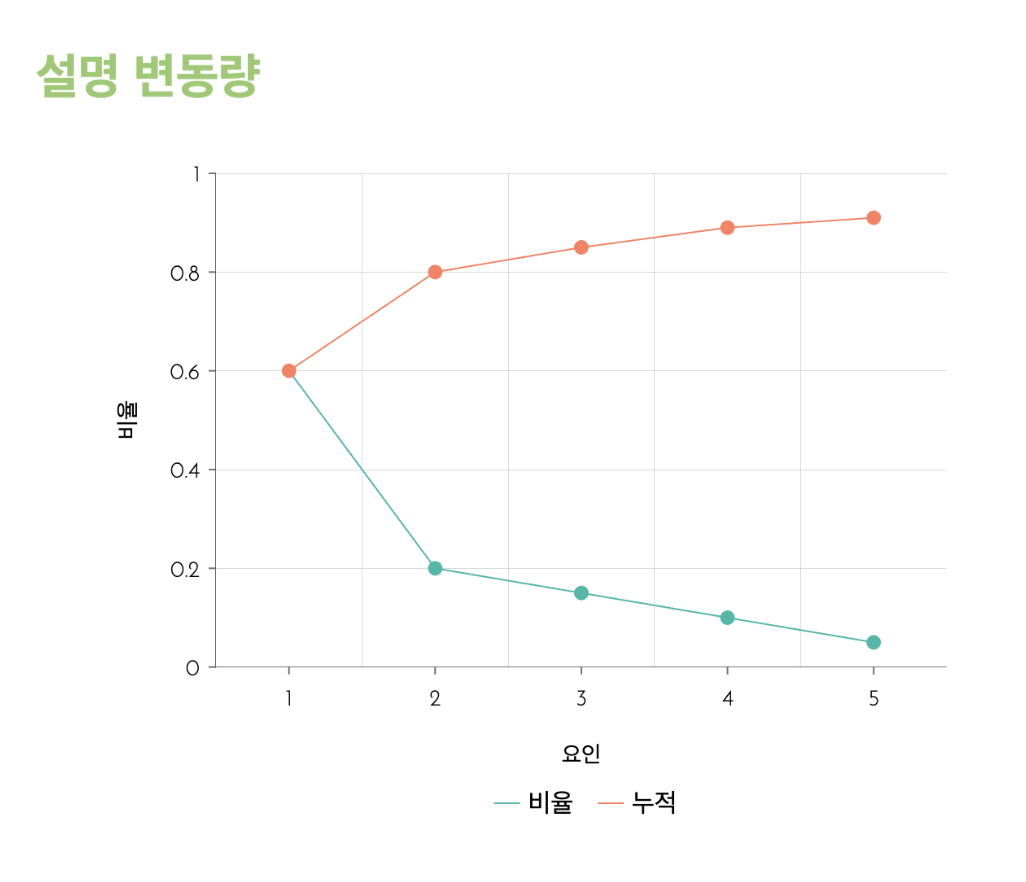
- 설명 변동량: 스크리 도표 값에 대한 보조 데이터로 활용
- 각 요인이 얼마나 중요한지 "비율"선을 통해 표시되며, 각 요인 증가에 따라 모수의 어느정도 비율을 설명하는 지 "누적"선을 통해 나타남
- 때문이 만약 모수의 90%를 설명하고 싶다면 k값은 5가 적합할 수 있음
- 카이저 규칙: 주성분 분석이나 요인 분석에서 사용되는 규칙으로, 고윳값이 1 이상인 주성분이나 요인만을 선택하는 것을 제안하는 방법
- 고윳값이 1보다 큰 주성분은 한 변수 이상의 정보를 포함하고 있다는 것을 의미
- 반면, 고윳값이 1보다 작은 주성분은 해당 주성분이 데이터의 한 변수보다도 적은 정보를 포함하고 있다는 것을 의미하기에 이러한 주성분들은 분석에서 제외하는 것을 추천
3. 덴드로그램
- 개요
- 유사도에 따라 비슷한 객체끼리 묶는 방법
